

The world is getting smarter day by day. Ranging from smartphones to smart security devices to self-driving cars, all things are powered by Artificial Intelligence (AI) and Machine Learning (ML). AI & ML technologies work with the help of huge amounts of data. Computers cannot process visual information the way humans do. The machines need to be told what they are interpreting and require context to form decisions. This is done with the help of data annotation.

AI Data annotation includes labeling or marking data to train machine learning algorithms. It ensures the scalability of AI or ML projects by identifying and labeling particular images, data, or videos to make it easier for machines to identify and classify information. Labeling guarantees that ML algorithms cannot compute vital attributes.
Data Annotation in AI & ML
The preliminary step in the Machine Learning lifecycle is data annotation. It helps build AI-powered technologies and provides meaning to the data. This, in turn, helps train ML algorithms.
When it comes to the AI process, data annotation is a key part of it. It is a human-led process of classifying and labeling data to help machines understand it. The process is not a one-time task but an ongoing activity throughout the Machine Learning lifecycle.
Data annotation is vital for AI & ML as it allows machines to learn from data and apply that learning to other data. This process of learning where you learn from one set of data and apply that learning to other data is called supervised learning. It is a form of Machine Learning which is beneficial for multiple applications like image classification, spam filtering, fraud detection, etc.
Data Annotation as a Component of the Machine Learning Lifecycle
Data annotation is a key component of the Machine Learning process as it makes it possible for machines to ‘see’ and comprehend images, text, videos, and speech. It is a premier step in the Machine Learning lifecycle, which is a cyclical process with multiple phases, each having its individual data annotation task.
The various stages of the cycle include the following:
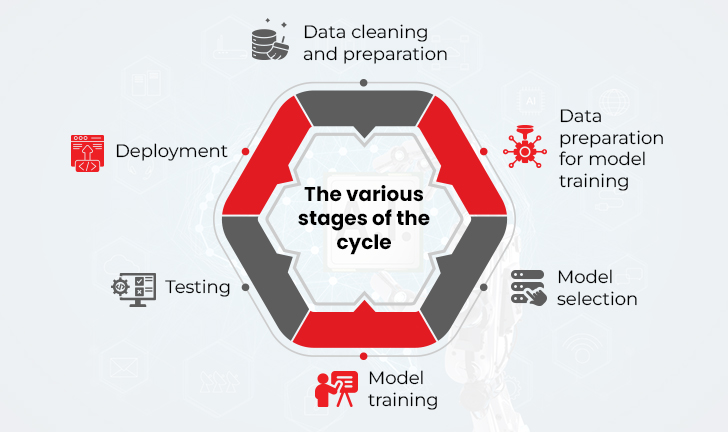
Data annotation for machine learning is a continuing process. The performance of your models is dependent on the quality of your data sets. Thus, it is important to continually improve your data sets by adding more annotations in the form of labels or data types. This process is called data augmentation. It includes adding new data to your existing datasets so that you can use them to boost the performance of your Machine Learning models.
Get Access to Quality Data Annotation Services
Scalability and Data Annotation
In the ML lifecycle, it is important to ensure scalability with data annotation. When your data set grows, It becomes challenging to keep yourself updated with the changes that should happen. AI data annotation solutions guarantee the scalability of your data sets not only for your organization but also for your partners who are sharing data with you.
Scalability in data annotation refers to the efficiency with which you handle huge volumes of data. If you need to annotate millions of images but the annotators available to you are limited, then the annotation job might take months or years to complete. In such a case, you should automate as much as you can so that humans don’t have to annotate every image manually. Data annotation creates training datasets that represent the target problem. These sets are big enough to support multiple models in your ML pipeline.
Understanding Ethics in AI Data Annotation
When it comes to data annotation, fairness becomes an important concern. The labeling of data, be it images or text, needs to effectively depict the content and not cause any hindrance to certain individuals or groups. For instance, if a dataset is being annotated with images of people, measures should be taken to include a wide range of genders, races, and body types. Annotators also need to be trained to identify and avoid any biases they might have that could affect their labeling.
The use of algorithms or pre-existing labeled data can also introduce bias in data annotation. When a dataset is biased, the output algorithm will also be biased, resulting in errors. To get rid of this problem, data annotators need to be trained to identify and correct any biases in the data and introduce varied experiences and perspectives into the process of annotation.
Transparency also plays a key role when it comes to the ethics of data annotation. Users need to have access to information about the way data was labeled and the limitations or biases that might be present. Also, the data annotators need to be transparent about their intentions and methods, and any conflicts of interest that might be there.
Perplexity and Burstiness are the two crucial factors in the data annotation process. Perplexity defines the complexity of the text and Burstiness helps compare the variations of sentences. As humans tend to write with greater burstiness, with some longer sentences alongside shorter ones, all sentences are generally more uniform. Thus, while annotating text data, it is vital to capture the rich complexities of human language and not just turn it into a uniform and dull dataset.
Summing Up
Data annotation helps machines understand text, images, speech, and videos as humans do. The chief purpose of data annotation is to make sure that Machine Learning algorithms receive training on high-quality data. This helps them learn from the training data and gradually improve their performance on real-world data.
The ethics of data annotation are vital to ensure fairness, transparency, and accuracy in the creation of meaningful data from huge datasets. Mindful consideration of biases and perspectives, transparency, and a complete representation of the complexities of language are significant for accurate annotation. This helps ensure that artificial intelligence and data analysis are not amplifying and promoting injustices, but taking steps to uncover them and offer solutions.
With AI and ML being used by almost every industry, data annotation cannot be overlooked. With more and more businesses adopting AI everyday, the trend of data annotation will only increase. Accurately annotated data helps determine if you’ll be able to build a high-performing AI & ML model that can be a solution to a complex business challenge.
Consulting data annotation companies is your best bet when you don’t have the resources or time to develop high-quality annotated data by yourself. Data annotation experts will not only help you save time and money but also swiftly scale your AI capabilities and devise Machine Learning solutions that best meet customer expectations and match the market requirements.


