

From healthcare advancements and autonomous vehicles to product recommendation chatbots and predictive analytics, AI and ML models are creatively disrupting lives and businesses altogether. Thus, ensuring the integrity of these systems’ foundational components becomes even more critical.
Data annotation, the process of labeling datasets to make them comprehensible for AI models, is a cornerstone of AI development. However, the accuracy and reliability of AI systems depend on the integrity of the data used to train them. Data integrity ensures that data used to train artificial intelligence models is accurate and reliable.

If the annotated data is erroneous, inconsistent, or unreliable, the inaccuracies propagate through the AI model, resulting in flawed outcomes. Or take it this way: the adage “garbage in, garbage out” is valid for AI projects. So, don’t be surprised when an AI model talks trash; instead, focus on the integrity of the data used!
Poor data integrity is one of the significant reasons why 70-80% of AI projects fail, even though they are brimming with immense potential to redefine businesses. Conversely, high-quality data ensures that AI models deliver precise and unbiased results.
Take facial recognition systems, where poorly annotated data may lead to inaccuracies in identifying individuals. Even worse, this disproportionately affects specific demographic groups. Similarly, errors in labeling images of road signs or pedestrians in datasets that train autonomous vehicles’ algorithms may result in tragic accidents. Thus, it’s evident how vital data integrity is and why the quality of data annotation is not just important but imperative.
Data Quality Issues in Annotation
Not all data is generated equally. Whether it’s videos, text, or images, data quality plays a key role in determining if the AI project would be successful or not. Take a look at the two common types of data annotation errors that hamper the model’s decision-making:
1. Data drift
Data drift is caused by gradual changes in data features and annotation labels over time. This leads to higher error rates in machine learning and rule-based models, resulting in inaccurate predictions, poor decision-making, and a loss of competitive edge. Additionally, data drift also results in financial losses and operational inefficiencies. So, to avoid data drift, periodic annotation review is necessary.
2. Anomalies
While data drift is a slow data change, anomalies are abrupt deviations caused by external events. The COVID-19 pandemic was an anomaly from the usual healthcare industry incidents. The experience and expertise of a seasoned data annotation company helps detect such anomalies, be it the slightest deviation or a huge shift, and switch from automated annotation tools to a more comprehensive human-in-the-loop approach when required.
KPIs and Metrics to Measure Quality in Data Annotation
Without strict QA protocols, inconsistencies, errors, and biases infiltrate the dataset. This limits its usage and undermines the performance of AI systems. On the other hand, a well-defined quality assurance (QA) process ensures high-standard data annotation by identifying and rectifying these issues. Here are some of the metrics and key performance indicators (KPIs) to get measurable insights into the accuracy and reliability of the data annotation process:
1. Inter-Annotator Agreement (IAA) Metrics
Though there are well-established guidelines for every data annotation project, some subjectivity may still creep in, impacting the results. This is where Inter-Annotator Agreement metrics help, ensuring every annotator follows a consistent approach across all categories. This metric measures the consistency among multiple annotators working on the same dataset. High IAA scores indicate annotators have a shared understanding of labeling criteria, ensuring uniformity in annotation.
2. Setting the Gold Standard for Annotation
A perfectly annotated dataset that illustrates what the annotation should look like is called a gold standard. It serves as a template or point of reference for all annotators and reviewers, regardless of their experience and skills. The gold standard establishes a performance benchmark for annotators, even if the labeling instructions change.
3. Scientific Tests to Determine Annotation Accuracy
Scientific tests help in evaluating the performance of annotators using tried-and-true formulas. Some of the standard tests include:
- Cronbach Alpha – This is a statistical test to ensure that annotations are in line with the defined data labeling standards. The reliability coefficient is marked with 1 for high similarity among the labels and 0 for completely unrelated labeling. Thus, it ensures that annotations are reliable and consistent throughout the dataset. Moreover, Cronbach’s Alpha test helps reassess the initial guidelines and make necessary revisions if annotators have any doubts. Due to this flexibility, the test is employed in pilot studies to resolve discrepancies in subsequent data labeling proactively.
- Cohen’s Kappa – This statistical coefficient helps measure the agreement between two annotators on a qualitative basis. Reviewers assign 1 for total agreement, -1 for total disagreement, and 0 for chance-level agreement when defining how to measure quality. This test takes chance agreement into consideration, making it a more reliable option. However, there’s one limitation: Cohen’s Kappa test measures accuracy only between two annotators. The formula is as follows, where Pr(a) is the predicted agreement among annotators and Pr(e) is the expected agreement among annotators:
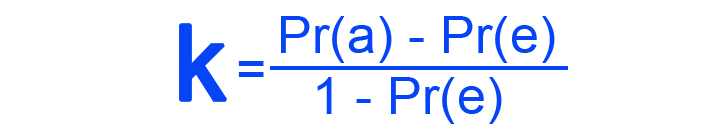
- Fleiss’ Kappa – Similar to Cohen’s Kappa, Fleiss’ Kappa uses category ratings to define agreement. It ranges from 0 to 1, where 1 is equal to a perfect agreement, and 0 is equal to no agreement. The difference is that three or more annotators are involved in Fliess’s test. The formula follows: P is the annotator agreement and Pe is the expected annotator agreement.
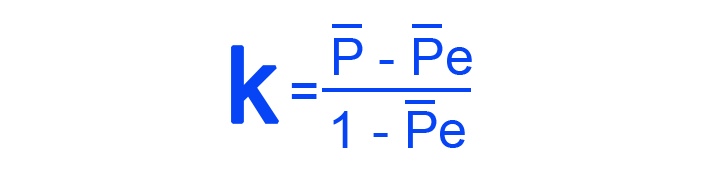
- Pairwise F1 – This metric considers both precision (how many annotations are correct) and recall (number of correct annotations compared to the ones that were missed), calculating a score from 0 to 1. 0 is a lack of precision and recall whereas 1 is equal to perfect precision and recall. The average of these two is equal to the F1 score. In projects with a gold standard, this metric is helpful as it helps evaluate the quality of labeled data against the gold standard. An important thing to note is that this metric doesn’t consider chance agreements. The formula is as follows:

- Krippendorff’s Alpha – No matter how many annotators are there, this metric evaluates how reliable their agreement is. It applies to different kinds of data, such as ratio, ordinal, and nominal. Krippendorf’s Alpha symbolizes a particular level of disagreement for every pair of labels. The values range from 0 to 1, 0 equating to perfect disagreement and 1 to perfect agreement. The formula is as follows, with pa as the weighted percent of agreement and pe as the chance weighted percent of agreement:
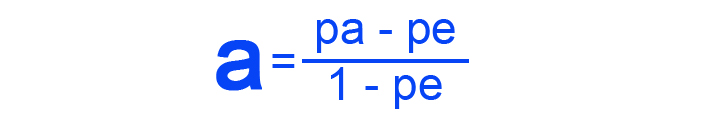
4. Consensus Algorithm
Multiple annotators working on tasks related to the same project may sometimes have different points of view. This is particularly true when the data in question calls for subjective judgment. Here assessing data entry quality control is an apt example of a consensus algorithm being useful.
True to its name, the algorithm provides an agreement on a single data point between multiple annotators. In practice, each annotator assigns a label to the defined data, and the consensus algorithm helps decide the final label and assess the quality of the data. This approach is generally used in manual annotation applications, such as image classification or sentiment analysis. Consensus agreement is the simplest method, as annotators can select the final label even through simple majority voting.
5. Random Sampling
This approach looks for errors by randomly selecting annotated data from a larger pool. This sample is compared to the consensus procedure and the gold standard to ensure the quality meets the project’s requirements. Areas with more significant annotation errors are easily identified with random samples.
Tackle data annotation challenges and elevate your ML Project
Best Practices in Data Annotation and Their Impact on AI Outcomes
Implementing best practices in data annotation is important for enhancing data quality and, by extension, the performance of AI systems. Here’s what all businesses should follow:
I) Define High-Quality Deliverables
Annotation guidelines provide annotators with detailed instructions, examples, and edge cases to reduce uncertainty. And, defining what constitutes high-quality deliverables ensures data accuracy and reduces inconsistency among annotators. Thus, the dataset meets the desired quality standards.
II) Advanced Annotation Tools
Companies looking to optimize their data annotation process must be equipped with advanced tools. AI data annotation tools help automate repetitive tasks, detect errors, and provide real-time feedback to annotators. Without apt tools to create bounding boxes or key points, the annotators won’t be able to complete the task at hand.
III) Implementing a Feedback Loop
Continuous feedback helps annotators improve their performance over time. Regular reviews and constructive feedback sessions ensure annotators remain aligned with project objectives and guidelines. Without a clear feedback mechanism, annotators may not realize whether their work is relevant.
IV) Training and Upskilling Annotators
The advancements in tools, technologies, and methodologies make data annotation a constantly evolving matrix. That said, human annotators must keep themselves up-to-date with the nitty-gritty of the process. Ongoing training and upskilling opportunities prove helpful as annotators hone themselves with the necessary knowledge and expertise.
V) Project Length and Scope
The length of the project directly impacts the annotation quality. Generally, annotators become more experienced if the project is of longer duration. Moreover, the project length also affects the budget; however, it must be considered when determining the level of accuracy stakeholders want to achieve. For instance, the cost of task labeling objective truth differs from the subjective answers during annotations.
Enhance AI Accuracy with Premium Data Annotation Services.
Impact of High-Quality Data Annotation on AI Outcomes
Data quality has a direct and evident impact on AI outcomes. Wondering what? High-quality annotations enable AI models to learn from accurate and consistent data, reducing the chances of errors and biases in predictions. Furthermore, well-annotated data expedites the training process, leading to accelerated development cycles and more reliable AI solutions.
The outcomes of accurate annotations are evident in industries such as healthcare, finance, and autonomous systems— impacting everything from patient diagnoses to risk assessments and operational safety.
End Thoughts
Data integrity plays a pivotal role in harnessing the full potential of AI by ensuring that these systems learn from unbiased, accurate, and consistent datasets. A well-structured quality assurance framework, guided by metrics like inter-annotator agreement, scientific tests, and consensus agreement, lays a rock-solid foundation for this process. Coupled with best practices, these measures enhance the quality of annotated data and mitigate the risks associated with flawed AI outcomes. And by investing in high standards for data annotation, businesses position themselves as leaders in innovation.


